Ship Fast and Rest Easy — Feature Management by LaunchDarkly

Testing, testing… and more testing
We want to test everything before going to production. We want to be safe, knowing that we are not breaking anything and knowing that customers will benefit and find these new features useful.
So we do thorough testing, or at least we try. We start from Dev, and we perform many tests there. Once developers feel confident enough, we push that version to QA, and we bombard in the lookout for bugs or errors. QA approves, and from then onwards, we should feel safe about launching the new version in production. However… we never are 100% sure. The amount of testing one can replicate in a lab is limited, and you can never know whether the new feature is a success or not until you face the final test: production. And for ML applications, this final testing in production becomes of the uttermost importance: you cannot really predict/simulate the many ways in which your users will use your product. You cannot really do unit testing of your models. Your new version may be a great improvement for some user segments, yet a severe degradation for others. We want to make data-driven decisions, so, how can we effectively gather real user feedback on new features, while minimizing the risk of complaints if things don’t go as expected?
Knowing that production is the final test, and that we may run into issues, teams usually are not too keen on deploying on Fridays: no one wants to receive an emergency call during the weekend.

Deploying in production is risky. However, as a business, we want to be able to ship new features fast, taking calculated risks. How can we speed up the process of deployment, while at the same time having a safety net to easily (and quickly) disable that new feature if hated by customers, or if it degrades performance? Do we really need to have a DevOps/MLOps team ready for roll-back to the previous version? Do we need to have our engineers on call? Or can we do better?
LaunchDarkly comes to the rescue. Marketed as the #1 Platform for Managing Feature Flags, it promises to give us the abilities to “Test Safely”, “Release Confidently”, “Control Dynamically” and “Measure Impact”.

We decided to give it a try and signed up for their 14-day free trial to test it in one of our projects for Machine Learning for Production course at Carnegie Mellon University: a movie recommendation system.
Trying the tool
LaunchDarkly comes with a quickstart guide that makes it very easy to get started. It can be integrated with several programming languages. for our project, we selected python.
- We start generating our requirements.txt file to download their package:
echo "launchdarkly-server-sdk==7.1.0" >> requirements.txt && pip install -r requirements.txt- To enable/disable the feature, we first need to add the library to the python file
import ldclient
from ldclient.config import Config- Next we set up the configuration, providing our SDK generated key
ldclient.set_config(Config(<enter_here_your_sdk_key>))- Finally, we get the connection with LaunchDarkly for the feature we want to enable/disable, and we just add an if statement to execute or not that new functionality
user = {
"key": "1652352",
"firstName": "Marta",
"lastName": "Mendez",
"custom": {
"groups": "beta_testers"
}
}
show_feature = ldclient.get().variation(<feature_name>, user, False)
if show_feature:
print("Showing your feature")
else:
print("Not showing your feature")
ldclient.get().close()As you can see, it is super easy to implement! And just as easily, we can add targeted features (by which we can control which users see a variation of a feature flag) by providing a user dictionary with the specific user details (or by using the generic “anonymous”).
We are going to implement three basic features that could potentially target different users.
Per user feature: considering movie genre
Our movie recommendation system currently operates on a collaborative filtering approach, where we provide recommendations for a certain user by finding users with similar tastes and selecting movies they liked.
What if we wanted to consider extra information, for example, movie genres, when making the recommendations? We would just have to define that new feature in LaunchDarkly, and then surround our code with the ldclient.
Creating the feature flag with the UI is super easy, just click on +Flag button in the right top corner, and fill in the details:
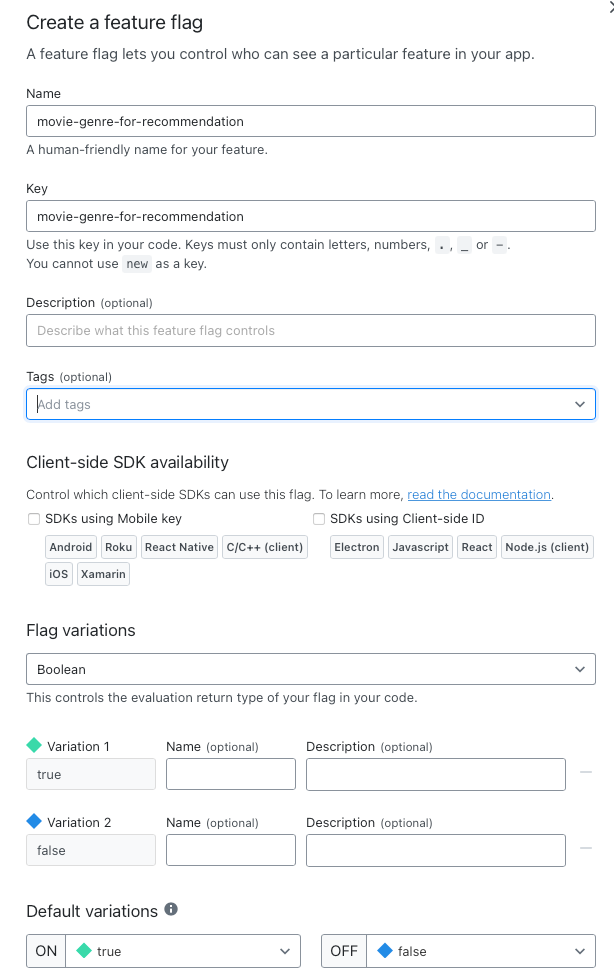
Let’s take things one step further, and target this feature for specific users! First thing you need to think about is what type of users you have in your application, and if you would like to have groups for which you would like to enable/disable the feature in bulk.
You can think of users from several approaches. Let’s try to see this by going back to our movie recommendation system. Currently, it is hosted in the cloud and it exposes a public API endpoint so end users (without authenticating) can request movie recommendations for specific user IDs (by passing it as an argument). Basically, right now one person can request recommendations for several different users (note the distinction with a Netflix-type scenario, in which the authorized user requests recommendations for him/her only). In our scenario, instead of toggling on/off the feature for a specific requested user ID, it would make more sense to toggle based on the user who is making the requests, so all the recommendations him/her gets are derived using the same ML model and features. If we were to apply the feature toggling on the requested user ID level instead, this could cause confusion to the end user who makes the request, because he/she may be getting recommendations that use different approaches depending on the user ID they are requesting.
To apply this approach, we would need to modify our API endpoint to include authentication so that we can identify the end user with several attributes (i.e: country, ID, IP, email…); and we can enable/disable our new feature (movie-genre-for-recommendation) in all the requests we serve for that user.

Within Feature Flags, we can select our flag and customize it. For example, let’s turn it on for our Spain and UK users:
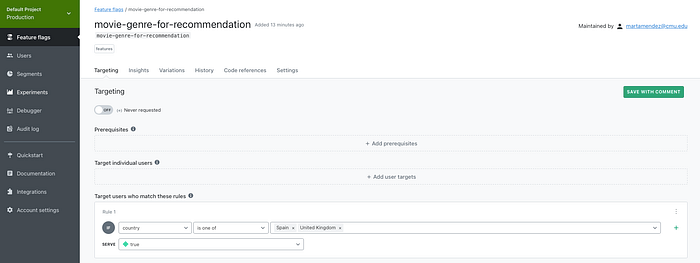
As you can see, we have left the Default rule as “false”, so any other user who is not from Spain or United Kingdom will not have the feature enabled.
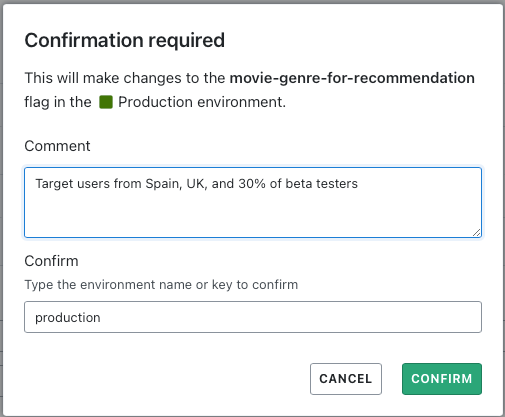
Another thing we love about the system is that, upon making changes, it prompts you for confirmation, and the type of environment where you want to deploy this changes into:
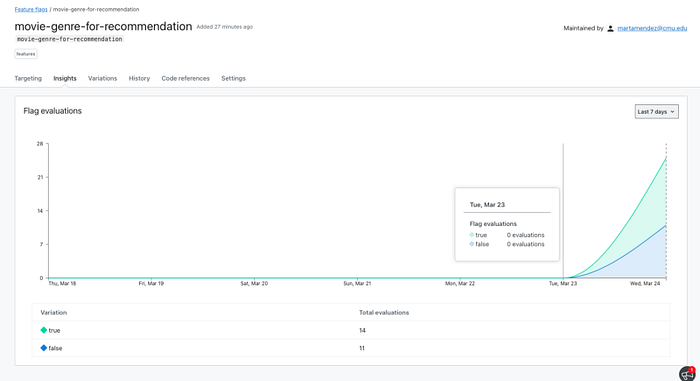
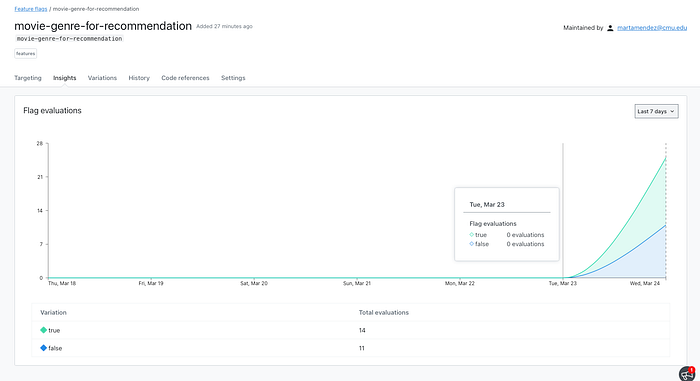
Under Insights tab, you can see the number of times the feature has been evaluated to true/false:
Per user feature: model version
What if we want to test out a new model in production? We could have a “model-version” feature that returns the version of the model we want to run (i.e: if ON, serve model 2, if OFF, serve default model 1):
model_version = ldclient.get().variation("model-version", user, False)
# Load the user-movie interaction matrixuser_movie_matrix = pd.read_pickle(f'model{model_version}_data/interaction_matrix.pkl')
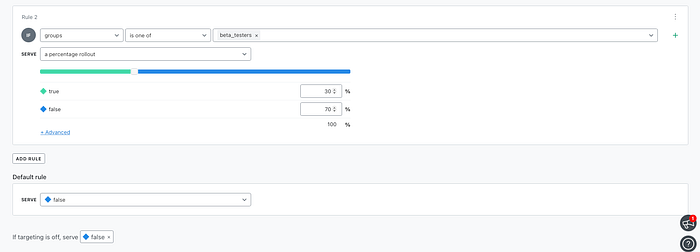
We could rollout this new model only to a percentage of our beta testers, a parameter that can be easily tweaked from the UI:
Global Feature: retraining the model
Another thing we really liked about the tool, is the versability it provides when defining the features. The flag variations allow as return types Boolean, String, Number or JSON. For our previous features, we tried the default, Boolean (either enable or disable the feature), and Number (the model version to test).
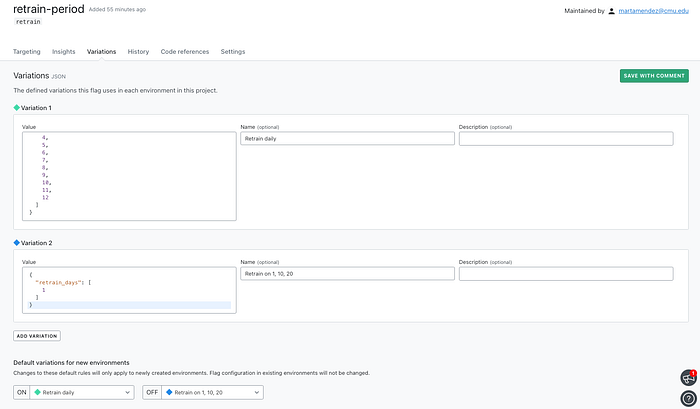
What if we wanted something more complex? For example, we could have a retrain-days feature that only retrains the model if the current day of the month matches one of our currently selected options for our feature (i.e: every day, only 1st of month). It is as easy as defining a custom JSON code on their UI, and modifying our code to check that JSON returned by LaunchDarkly!
Strengths and Limitations
Strengths:
- Very intuitive UI, you can get it running in less than 5 minutes
- Quickly enable/disable features in production, in a matter of milliseconds!
- Can target features to individual users/groups
- Can do % rollouts
- Can return different types (Boolean/String/Number/JSON) for each feature, which gives great versatility in the things one can achieve
- Prompts the user for message and confirmation of environment to deploy the changes
- Can integrate with GitHub, to see directly from LaunchDarkly where you are invoking a certain feature in your code
- Log tracks all the modifications made by users
Limitations:
- Cost: it is not free, the starter subscription is $75/month, and the professional $325/month
- When applying features per group level, the insights graph does not show which groups matched for the true/false eval. It would be useful to know to have extra insight
Summary
This is a great tool that will allow you to deploy faster in production, whith the security of being able to toggle on/off features, not only globally, but also with more granularity, deploying only for certain user groups or even individual users.
It would definitely give me ease of mind on production-level deployments, knowing that rolling back on a new feature can be done in just 200ms.
The experiments tab was not available to test, but seems very interesting to gain more insight on how a user interacts with the application upon seeing one of our new features:
When a user performs a metric-tracked action in your application after they encounter a feature flag, the experiment logs an event.
For example, an experiment might show that users are more likely to convert by clicking “Checkout” when the Checkout button is a certain color. The metric you would track to measure that is when they click on the Checkout button. It would be connected to a flag serving four variations, each of which is a different color for the button.
